背景
在很多公司都觉得odoo系统只适合中小企业,究其原因,大部分都是认为是odoo性能比较差,甚至有同学认为是python性能影响,诚然python性能比不过java这种编译静态型语言,但是性能不至于像odoo表现这么差,在研究其源码后,我发现odoo现有架构天然缺陷。
odoo现有架构
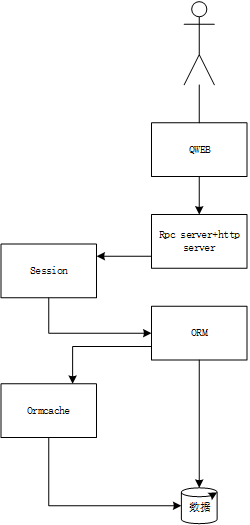
odoo本身架构是一个单体运用,session 是通过文件系统存储的,ormcache 是基于运用自身内存的,我们首先分析下这两块代码,本文代码基于odoo10社区版
session部分
class Root(object):
"""Root WSGI application for the OpenERP Web Client.
"""
def __init__(self):
self._loaded = False
@lazy_property
def session_store(self):
# Setup http sessions
path = odoo.tools.config.session_dir
_logger.debug('HTTP sessions stored in: %s', path)
return werkzeug.contrib.sessions.FilesystemSessionStore(path, session_class=OpenERPSession)
@lazy_property
def nodb_routing_map(self):
_logger.info("Generating nondb routing")
return routing_map([''] + odoo.conf.server_wide_modules, True)
def __call__(self, environ, start_response):
""" Handle a WSGI request
"""
if not self._loaded:
self._loaded = True
self.load_addons()
return self.dispatch(environ, start_response)
def load_addons(self):
""" Load all addons from addons path containing static files and
controllers and configure them. """
# TODO should we move this to ir.http so that only configured modules are served ?
statics = {}
for addons_path in odoo.modules.module.ad_paths:
for module in sorted(os.listdir(str(addons_path))):
if module not in addons_module:
mod_path = opj(addons_path, module)
manifest_path = module_manifest(mod_path)
path_static = opj(addons_path, module, 'static')
if manifest_path and os.path.isdir(path_static):
manifest = ast.literal_eval(open(manifest_path).read())
if not manifest.get('installable', True):
continue
manifest['addons_path'] = addons_path
_logger.debug("Loading %s", module)
if 'odoo.addons' in sys.modules:
m = __import__('odoo.addons.' + module)
else:
m = None
addons_module[module] = m
addons_manifest[module] = manifest
statics['/%s/static' % module] = path_static
if statics:
_logger.info("HTTP Configuring static files")
app = werkzeug.wsgi.SharedDataMiddleware(self.dispatch, statics, cache_timeout=STATIC_CACHE)
self.dispatch = DisableCacheMiddleware(app)
def setup_session(self, httprequest):
# recover or create session
session_gc(self.session_store)
sid = httprequest.args.get('session_id')
explicit_session = True
if not sid:
sid = httprequest.headers.get("X-Openerp-Session-Id")
if not sid:
sid = httprequest.cookies.get('session_id')
explicit_session = False
if sid is None:
httprequest.session = self.session_store.new()
else:
httprequest.session = self.session_store.get(sid)
return explicit_session
def setup_db(self, httprequest):
db = httprequest.session.db
# Check if session.db is legit
if db:
if db not in db_filter([db], httprequest=httprequest):
_logger.warn("Logged into database '%s', but dbfilter "
"rejects it; logging session out.", db)
httprequest.session.logout()
db = None
if not db:
httprequest.session.db = db_monodb(httprequest)
def setup_lang(self, httprequest):
if "lang" not in httprequest.session.context:
alang = httprequest.accept_languages.best or "en-US"
try:
code, territory, _, _ = babel.core.parse_locale(alang, sep='-')
if territory:
lang = '%s_%s' % (code, territory)
else:
lang = babel.core.LOCALE_ALIASES[code]
except (ValueError, KeyError):
lang = 'en_US'
httprequest.session.context["lang"] = lang
def get_request(self, httprequest):
# deduce type of request
if httprequest.args.get('jsonp'):
return JsonRequest(httprequest)
if httprequest.mimetype in ("application/json", "application/json-rpc"):
return JsonRequest(httprequest)
else:
return HttpRequest(httprequest)
def get_response(self, httprequest, result, explicit_session):
if isinstance(result, Response) and result.is_qweb:
try:
result.flatten()
except(Exception), e:
if request.db:
result = request.registry['ir.http']._handle_exception(e)
else:
raise
if isinstance(result, basestring):
response = Response(result, mimetype='text/html')
else:
response = result
# save to cache if requested and possible
if getattr(request, 'cache_save', False) and response.status_code == 200:
response.freeze()
r = response.response
if isinstance(r, list) and len(r) == 1 and isinstance(r[0], str):
request.registry.cache[request.cache_save] = {
'content': r[0],
'mimetype': response.headers['Content-Type'],
'time': time.time(),
}
if httprequest.session.should_save:
if httprequest.session.rotate:
self.session_store.delete(httprequest.session)
httprequest.session.sid = self.session_store.generate_key()
httprequest.session.modified = True
self.session_store.save(httprequest.session)
# We must not set the cookie if the session id was specified using a http header or a GET parameter.
# There are two reasons to this:
# - When using one of those two means we consider that we are overriding the cookie, which means creating a new
# session on top of an already existing session and we don't want to create a mess with the 'normal' session
# (the one using the cookie). That is a special feature of the Session Javascript class.
# - It could allow session fixation attacks.
if not explicit_session and hasattr(response, 'set_cookie'):
response.set_cookie('session_id', httprequest.session.sid, max_age=90 * 24 * 60 * 60)
return response
def dispatch(self, environ, start_response):
"""
Performs the actual WSGI dispatching for the application.
"""
try:
httprequest = werkzeug.wrappers.Request(environ)
httprequest.app = self
httprequest.parameter_storage_class = werkzeug.datastructures.ImmutableOrderedMultiDict
threading.current_thread().url = httprequest.url
explicit_session = self.setup_session(httprequest)
self.setup_db(httprequest)
self.setup_lang(httprequest)
request = self.get_request(httprequest)
def _dispatch_nodb():
try:
func, arguments = self.nodb_routing_map.bind_to_environ(request.httprequest.environ).match()
except werkzeug.exceptions.HTTPException, e:
return request._handle_exception(e)
request.set_handler(func, arguments, "none")
result = request.dispatch()
return result
with request:
db = request.session.db
if db:
try:
odoo.registry(db).check_signaling()
with odoo.tools.mute_logger('odoo.sql_db'):
ir_http = request.registry['ir.http']
except (AttributeError, psycopg2.OperationalError, psycopg2.ProgrammingError):
# psycopg2 error or attribute error while constructing
# the registry. That means either
# - the database probably does not exists anymore
# - the database is corrupted
# - the database version doesnt match the server version
# Log the user out and fall back to nodb
request.session.logout()
# If requesting /web this will loop
if request.httprequest.path == '/web':
result = werkzeug.utils.redirect('/web/database/selector')
else:
result = _dispatch_nodb()
else:
result = ir_http._dispatch()
ir_http.pool.signal_caches_change()
else:
result = _dispatch_nodb()
response = self.get_response(httprequest, result, explicit_session)
return response(environ, start_response)
except werkzeug.exceptions.HTTPException, e:
return e(environ, start_response)
def get_db_router(self, db):
if not db:
return self.nodb_routing_map
return request.registry['ir.http'].routing_map()
这是odoo后端在接受到请求后,第一个处理对象ROOT全部代码,通过web server 种的hook,将会依次调用setup_session,setup_db,setup_lang等方法获得处理后的http request 对象。这里需要注意是session_store方法,注意他被lazy_property装饰器装饰过,简单可以理解为这个是属性,直接根据self.sesson_store可以获得其值,这个方法主要返回一个session处理器,odoo原生是使用OpenERPSession,是基于werkzeug.contrib.sessions.Session这个python原装包,其代码如下
class OpenERPSession(werkzeug.contrib.sessions.Session):
def __init__(self, *args, **kwargs):
self.inited = False
self.modified = False
self.rotate = False
super(OpenERPSession, self).__init__(*args, **kwargs)
self.inited = True
self._default_values()
self.modified = False
def __getattr__(self, attr):
return self.get(attr, None)
def __setattr__(self, k, v):
if getattr(self, "inited", False):
try:
object.__getattribute__(self, k)
except:
return self.__setitem__(k, v)
object.__setattr__(self, k, v)
def authenticate(self, db, login=None, password=None, uid=None):
"""
Authenticate the current user with the given db, login and
password. If successful, store the authentication parameters in the
current session and request.
:param uid: If not None, that user id will be used instead the login
to authenticate the user.
"""
if uid is None:
wsgienv = request.httprequest.environ
env = dict(
base_location=request.httprequest.url_root.rstrip('/'),
HTTP_HOST=wsgienv['HTTP_HOST'],
REMOTE_ADDR=wsgienv['REMOTE_ADDR'],
)
uid = dispatch_rpc('common', 'authenticate', [db, login, password, env])
else:
security.check(db, uid, password)
self.db = db
self.uid = uid
self.login = login
self.password = password
request.uid = uid
request.disable_db = False
if uid: self.get_context()
return uid
def check_security(self):
"""
Check the current authentication parameters to know if those are still
valid. This method should be called at each request. If the
authentication fails, a :exc:`SessionExpiredException` is raised.
"""
if not self.db or not self.uid:
raise SessionExpiredException("Session expired")
security.check(self.db, self.uid, self.password)
def logout(self, keep_db=False):
for k in self.keys():
if not (keep_db and k == 'db'):
del self[k]
self._default_values()
self.rotate = True
def _default_values(self):
self.setdefault("db", None)
self.setdefault("uid", None)
self.setdefault("login", None)
self.setdefault("password", None)
self.setdefault("context", {})
def get_context(self):
"""
Re-initializes the current user's session context (based on his
preferences) by calling res.users.get_context() with the old context.
:returns: the new context
"""
assert self.uid, "The user needs to be logged-in to initialize his context"
self.context = request.env['res.users'].context_get() or {}
self.context['uid'] = self.uid
self._fix_lang(self.context)
return self.context
def _fix_lang(self, context):
""" OpenERP provides languages which may not make sense and/or may not
be understood by the web client's libraries.
Fix those here.
:param dict context: context to fix
"""
lang = context.get('lang')
# inane OpenERP locale
if lang == 'ar_AR':
lang = 'ar'
# lang to lang_REGION (datejs only handles lang_REGION, no bare langs)
if lang in babel.core.LOCALE_ALIASES:
lang = babel.core.LOCALE_ALIASES[lang]
context['lang'] = lang or 'en_US'
def save_action(self, action):
"""
This method store an action object in the session and returns an integer
identifying that action. The method get_action() can be used to get
back the action.
:param the_action: The action to save in the session.
:type the_action: anything
:return: A key identifying the saved action.
:rtype: integer
"""
saved_actions = self.setdefault('saved_actions', {"next": 1, "actions": {}})
# we don't allow more than 10 stored actions
if len(saved_actions["actions"]) >= 10:
del saved_actions["actions"][min(saved_actions["actions"])]
key = saved_actions["next"]
saved_actions["actions"][key] = action
saved_actions["next"] = key + 1
self.modified = True
return key
def get_action(self, key):
"""
Gets back a previously saved action. This method can return None if the action
was saved since too much time (this case should be handled in a smart way).
:param key: The key given by save_action()
:type key: integer
:return: The saved action or None.
:rtype: anything
"""
saved_actions = self.get('saved_actions', {})
return saved_actions.get("actions", {}).get(key)
def save_request_data(self):
import uuid
req = request.httprequest
files = werkzeug.datastructures.MultiDict()
# NOTE we do not store files in the session itself to avoid loading them in memory.
# By storing them in the session store, we ensure every worker (even ones on other
# servers) can access them. It also allow stale files to be deleted by `session_gc`.
for f in req.files.values():
storename = 'werkzeug_%s_%s.file' % (self.sid, uuid.uuid4().hex)
path = os.path.join(root.session_store.path, storename)
with open(path, 'w') as fp:
f.save(fp)
files.add(f.name, (storename, f.filename, f.content_type))
self['serialized_request_data'] = {
'form': req.form,
'files': files,
}
@contextlib.contextmanager
def load_request_data(self):
data = self.pop('serialized_request_data', None)
files = werkzeug.datastructures.MultiDict()
try:
if data:
# regenerate files filenames with the current session store
for name, (storename, filename, content_type) in data['files'].iteritems():
path = os.path.join(root.session_store.path, storename)
files.add(name, (path, filename, content_type))
yield werkzeug.datastructures.CombinedMultiDict([data['form'], files])
else:
yield None
finally:
# cleanup files
for f, _, _ in files.values():
try:
os.unlink(f)
except IOError:
pass
这部分代码是处理session具体方法,比如登陆,退出,等相关处理办法,可以理解为动作类,注意这个类中使用了的@contextlib.contextmanager装饰器 这是为了将构建的http request对象与session处理类保证其上下文一直。
思路通过redis改造session处理办法,从而让odoo具有横向扩张的可能性
Root类中session_store方法替换werkzeug.contrib.sessions.FilesystemSessionStore官方包,并实现其save,delete,get,list等行为
特别提示session_gc这个方法需要在外面处理下,不然他还会去删除存储本地session文件而不是redis缓存,造成找不到文件从而造成500错误。
ormcache改造
ormcache分为两部分,一部分为系统刚启动时候作为模块载入缓存这部分代码主要在modules模块中的registry.py
中,其功能主要保证各个包载入顺序,从而让python模块正确动态载入覆盖相关行为,其缓存内容多是类和方法,不容易对其使用reids缓存,其主要困难是,模型方法中使用 的self.env保存的对象或者方法无法被序列化,这部分如果有高手成功了改造可以联系我(邮箱:songyuchaoemail@163.com),我主要改造部分为模型中存在的model.pool.cache这里面缓存,这部分大部分都是正常类型数据缓存,首先我们先分析odoo自身LRU缓存
class LRU(object):
"""
Implementation of a length-limited O(1) LRU queue.
Built for and used by PyPE:
http://pype.sourceforge.net
Copyright 2003 Josiah Carlson.
"""
def __init__(self, count, pairs=[]):
self._lock = threading.RLock()
self.count = max(count, 1)
self.d = {}
self.first = None
self.last = None
for key, value in pairs:
self[key] = value
@synchronized()
def __contains__(self, obj):
return obj in self.d
def get(self, obj, val=None):
try:
return self[obj]
except KeyError:
return val
@synchronized()
def __getitem__(self, obj):
a = self.d[obj].me
self[a[0]] = a[1]
return a[1]
@synchronized()
def __setitem__(self, obj, val):
if obj in self.d:
del self[obj]
nobj = LRUNode(self.last, (obj, val))
if self.first is None:
self.first = nobj
if self.last:
self.last.next = nobj
self.last = nobj
self.d[obj] = nobj
if len(self.d) > self.count:
if self.first == self.last:
self.first = None
self.last = None
return
a = self.first
a.next.prev = None
self.first = a.next
a.next = None
del self.d[a.me[0]]
del a
@synchronized()
def __delitem__(self, obj):
nobj = self.d[obj]
if nobj.prev:
nobj.prev.next = nobj.next
else:
self.first = nobj.next
if nobj.next:
nobj.next.prev = nobj.prev
else:
self.last = nobj.prev
del self.d[obj]
@synchronized()
def __iter__(self):
cur = self.first
while cur is not None:
cur2 = cur.next
yield cur.me[1]
cur = cur2
@synchronized()
def __len__(self):
return len(self.d)
@synchronized()
def iteritems(self):
cur = self.first
while cur is not None:
cur2 = cur.next
yield cur.me
cur = cur2
@synchronized()
def iterkeys(self):
return iter(self.d)
@synchronized()
def itervalues(self):
for i, j in self.iteritems():
yield j
@synchronized()
def keys(self):
return self.d.keys()
@synchronized()
def pop(self, key):
v = self[key]
del self[key]
return v
@synchronized()
def clear(self):
self.d = {}
self.first = None
self.last = None
其代码本身代码 逻辑并不复杂,但是大家需要注意其大量使用的synchronized装饰器,为什么odoo开启works后,性能蜜汁无效,多与这部分有关,下面是这个装饰器源代码
def synchronized(lock_attr='_lock'):
def decorator(func):
@wraps(func)
def wrapper(self, *args, **kwargs):
lock = getattr(self, lock_attr)
try:
lock.acquire()
return func(self, *args, **kwargs)
finally:
lock.release()
return wrapper
return decorator
odoo自身的LRU 为了保证数据一致性,为这个类加入一把锁,在多线程情况下,多个线程抢夺这边锁会造成GIL问题(什么是GIL问题自行goggle)
ormcache改造思路,通过使用reids自身单线程数据一致性(相当于乐观锁)以及其强大性能将odoo从一致性问题造成性能衰减解放出来,并且在分布式部署中共享缓存。
改造代码
class RedisLRU(object):
def __init__(self,db_name):
self.redis = RedisPoolConnection()
self.db_name = "".join(("ormcache:",db_name))
def __getitem__(self, item):
if self._check_name(item[1].__name__):
raise KeyError
table_name, key = self.key(item)
val = self.redis.hget(table_name, key)
if not val:
raise KeyError
obj = self.to_obj(val)
return obj
def to_obj(self, val):
loads = dill.loads(zlib.decompress(val))
return loads
def key(self, item):
print item
if len(item)== 1:
return self.db_name,item[0]
item_list = item[1:-1]
fn_name = item[1].__name__
if len(item_list)>1:
return self.db_name, (item[0],fn_name,)+ item_list[1:-1]
else:
return self.db_name,(item[0],fn_name,)
def _check_name(self, method):
return method in ("_compute_domain")
def __setitem__(self, key, value):
if isinstance(value, (str, int, list, dict, set)):
dumps = self._str_zlib(value)
db_name, key = self.key(key)
self.redis.hset(db_name, key, dumps)
def _str_zlib(self, value):
dumps = zlib.compress(dill.dumps(value))
return dumps
def __delitem__(self, key):
self.redis.delete(*self.key(key))
def pop(self, key):
key = self.key(key)
val = self.redis.get(key)
self.redis.delete(key)
if not val:
raise KeyError
return val
def get(self, key, val=None):
table_name, key = self.get(key)
return self.redis.hget(table_name, key, val)
def get_cache_time(self):
seconds = self.get_config_value("ormcache_expire") or ONE_WEEK_IN_SECONDS
return seconds + random.randint(0, 9)
def get_config_value(self, key, default=None):
return odoo.tools.config.get(key, default)
def clear(self):
self.redis.delete(self.db_name)
def iteritems(self):
hgetall = self.redis.hgetall(self.db_name)
for key, val in hgetall.iteritems():
yield {key, self.to_obj(val)}
def iterkeys(self):
return iter(self.redis.hgetall(self.db_name))
def itervalues(self):
for key, v in self.redis.hgetall(self.db_name).iteritems():
yield v
def keys(self):
return self.redis.hgetall(self.db_name).keys()
def __len__(self):
self.redis.keys("ormcache*")
静态文件改造
odoo将通过less编译的文件存储于数据库ir_attachment表中,url表示路径,从而造成两方面问题,第一静态文件请求需要经过数据库查询,第二odoo服务器本身还要处理静态文件,
改造思路就是将静态文件直接存储到文件系统中,而不是通过数据库再转义下,并且通过nginx直接代理出去,降低odoo服务器处理静态文件的压力。
源码分析
class IrAttachment(models.Model):
"""Attachments are used to link binary files or url to any openerp document.
External attachment storage
---------------------------
The computed field ``datas`` is implemented using ``_file_read``,
``_file_write`` and ``_file_delete``, which can be overridden to implement
other storage engines. Such methods should check for other location pseudo
uri (example: hdfs://hadoopserver).
The default implementation is the file:dirname location that stores files
on the local filesystem using name based on their sha1 hash
"""
_name = 'ir.attachment'
_order = 'id desc'
@api.depends('res_model', 'res_id')
def _compute_res_name(self):
for attachment in self:
if attachment.res_model and attachment.res_id:
record = self.env[attachment.res_model].browse(attachment.res_id)
attachment.res_name = record.display_name
@api.model
def _storage(self):
return self.env['ir.config_parameter'].sudo().get_param('ir_attachment.location', 'file')
@api.model
def _filestore(self):
return config.filestore(self._cr.dbname)
@api.model
def force_storage(self):
"""Force all attachments to be stored in the currently configured storage"""
if not self.env.user._is_admin():
raise AccessError(_('Only administrators can execute this action.'))
# domain to retrieve the attachments to migrate
domain = {
'db': [('store_fname', '!=', False)],
'file': [('db_datas', '!=', False)],
}[self._storage()]
for attach in self.search(domain):
attach.write({'datas': attach.datas})
return True
@api.model
def _full_path(self, path):
# sanitize path
path = re.sub('[.]', '', path)
path = path.strip('/\\')
return os.path.join(self._filestore(), path)
@api.model
def _get_path(self, bin_data, sha):
# retro compatibility
fname = sha[:3] + '/' + sha
full_path = self._full_path(fname)
if os.path.isfile(full_path):
return fname, full_path # keep existing path
# scatter files across 256 dirs
# we use '/' in the db (even on windows)
fname = sha[:2] + '/' + sha
full_path = self._full_path(fname)
dirname = os.path.dirname(full_path)
if not os.path.isdir(dirname):
os.makedirs(dirname)
return fname, full_path
@api.model
def _file_read(self, fname, bin_size=False):
full_path = self._full_path(fname)
r = ''
try:
if bin_size:
r = human_size(os.path.getsize(full_path))
else:
r = open(full_path,'rb').read().encode('base64')
except (IOError, OSError):
_logger.info("_read_file reading %s", full_path, exc_info=True)
return r
@api.model
def _file_write(self, value, checksum):
bin_value = value.decode('base64')
fname, full_path = self._get_path(bin_value, checksum)
if not os.path.exists(full_path):
try:
with open(full_path, 'wb') as fp:
fp.write(bin_value)
# add fname to checklist, in case the transaction aborts
self._mark_for_gc(fname)
except IOError:
_logger.info("_file_write writing %s", full_path, exc_info=True)
return fname
@api.model
def _file_delete(self, fname):
# simply add fname to checklist, it will be garbage-collected later
self._mark_for_gc(fname)
def _mark_for_gc(self, fname):
""" Add ``fname`` in a checklist for the filestore garbage collection. """
# we use a spooldir: add an empty file in the subdirectory 'checklist'
full_path = os.path.join(self._full_path('checklist'), fname)
if not os.path.exists(full_path):
dirname = os.path.dirname(full_path)
if not os.path.isdir(dirname):
with tools.ignore(OSError):
os.makedirs(dirname)
open(full_path, 'ab').close()
@api.model
def _file_gc(self):
""" Perform the garbage collection of the filestore. """
if self._storage() != 'file':
return
# Continue in a new transaction. The LOCK statement below must be the
# first one in the current transaction, otherwise the database snapshot
# used by it may not contain the most recent changes made to the table
# ir_attachment! Indeed, if concurrent transactions create attachments,
# the LOCK statement will wait until those concurrent transactions end.
# But this transaction will not see the new attachements if it has done
# other requests before the LOCK (like the method _storage() above).
cr = self._cr
cr.commit()
# prevent all concurrent updates on ir_attachment while collecting!
cr.execute("LOCK ir_attachment IN SHARE MODE")
# retrieve the file names from the checklist
checklist = {}
for dirpath, _, filenames in os.walk(self._full_path('checklist')):
dirname = os.path.basename(dirpath)
for filename in filenames:
fname = "%s/%s" % (dirname, filename)
checklist[fname] = os.path.join(dirpath, filename)
# determine which files to keep among the checklist
whitelist = set()
for names in cr.split_for_in_conditions(checklist):
cr.execute("SELECT store_fname FROM ir_attachment WHERE store_fname IN %s", [names])
whitelist.update(row[0] for row in cr.fetchall())
# remove garbage files, and clean up checklist
removed = 0
for fname, filepath in checklist.iteritems():
if fname not in whitelist:
try:
os.unlink(self._full_path(fname))
removed += 1
except (OSError, IOError):
_logger.info("_file_gc could not unlink %s", self._full_path(fname), exc_info=True)
with tools.ignore(OSError):
os.unlink(filepath)
# commit to release the lock
cr.commit()
_logger.info("filestore gc %d checked, %d removed", len(checklist), removed)
@api.depends('store_fname', 'db_datas')
def _compute_datas(self):
bin_size = self._context.get('bin_size')
for attach in self:
if attach.store_fname:
attach.datas = self._file_read(attach.store_fname, bin_size)
else:
attach.datas = attach.db_datas
def _inverse_datas(self):
location = self._storage()
for attach in self:
# compute the fields that depend on datas
value = attach.datas
bin_data = value and value.decode('base64') or ''
vals = {
'file_size': len(bin_data),
'checksum': self._compute_checksum(bin_data),
'index_content': self._index(bin_data, attach.datas_fname, attach.mimetype),
'store_fname': False,
'db_datas': value,
}
if value and location != 'db':
# save it to the filestore
vals['store_fname'] = self._file_write(value, vals['checksum'])
vals['db_datas'] = False
# take current location in filestore to possibly garbage-collect it
fname = attach.store_fname
# write as superuser, as user probably does not have write access
super(IrAttachment, attach.sudo()).write(vals)
if fname:
self._file_delete(fname)
def _compute_checksum(self, bin_data):
""" compute the checksum for the given datas
:param bin_data : datas in its binary form
"""
# an empty file has a checksum too (for caching)
return hashlib.sha1(bin_data or '').hexdigest()
def _compute_mimetype(self, values):
""" compute the mimetype of the given values
:param values : dict of values to create or write an ir_attachment
:return mime : string indicating the mimetype, or application/octet-stream by default
"""
mimetype = None
if values.get('mimetype'):
mimetype = values['mimetype']
if not mimetype and values.get('datas_fname'):
mimetype = mimetypes.guess_type(values['datas_fname'])[0]
if not mimetype and values.get('url'):
mimetype = mimetypes.guess_type(values['url'])[0]
if values.get('datas') and (not mimetype or mimetype == 'application/octet-stream'):
mimetype = guess_mimetype(values['datas'].decode('base64'))
return mimetype or 'application/octet-stream'
def _check_contents(self, values):
mimetype = values['mimetype'] = self._compute_mimetype(values)
xml_like = 'ht' in mimetype or 'xml' in mimetype # hta, html, xhtml, etc.
force_text = (xml_like and (not self.env.user._is_admin() or
self.env.context.get('attachments_mime_plainxml')))
if force_text:
values['mimetype'] = 'text/plain'
return values
@api.model
def _index(self, bin_data, datas_fname, file_type):
""" compute the index content of the given filename, or binary data.
This is a python implementation of the unix command 'strings'.
:param bin_data : datas in binary form
:return index_content : string containing all the printable character of the binary data
"""
index_content = False
if file_type:
index_content = file_type.split('/')[0]
if index_content == 'text': # compute index_content only for text type
words = re.findall("[^\x00-\x1F\x7F-\xFF]{4,}", bin_data)
index_content = ustr("\n".join(words))
return index_content
name = fields.Char('Attachment Name', required=True)
datas_fname = fields.Char('File Name')
description = fields.Text('Description')
res_name = fields.Char('Resource Name', compute='_compute_res_name', store=True)
res_model = fields.Char('Resource Model', readonly=True, help="The database object this attachment will be attached to.")
res_field = fields.Char('Resource Field', readonly=True)
res_id = fields.Integer('Resource ID', readonly=True, help="The record id this is attached to.")
create_date = fields.Datetime('Date Created', readonly=True)
create_uid = fields.Many2one('res.users', string='Owner', readonly=True)
company_id = fields.Many2one('res.company', string='Company', change_default=True,
default=lambda self: self.env['res.company']._company_default_get('ir.attachment'))
type = fields.Selection([('url', 'URL'), ('binary', 'File')],
string='Type', required=True, default='binary', change_default=True,
help="You can either upload a file from your computer or copy/paste an internet link to your file.")
url = fields.Char('Url', index=True, size=1024)
public = fields.Boolean('Is public document')
# the field 'datas' is computed and may use the other fields below
datas = fields.Binary(string='File Content', compute='_compute_datas', inverse='_inverse_datas')
db_datas = fields.Binary('Database Data')
store_fname = fields.Char('Stored Filename')
file_size = fields.Integer('File Size', readonly=True)
checksum = fields.Char("Checksum/SHA1", size=40, index=True, readonly=True)
mimetype = fields.Char('Mime Type', readonly=True)
index_content = fields.Text('Indexed Content', readonly=True, prefetch=False)
@api.model_cr_context
def _auto_init(self):
res = super(IrAttachment, self)._auto_init()
self._cr.execute('SELECT indexname FROM pg_indexes WHERE indexname = %s', ('ir_attachment_res_idx',))
if not self._cr.fetchone():
self._cr.execute('CREATE INDEX ir_attachment_res_idx ON ir_attachment (res_model, res_id)')
self._cr.commit()
return res
@api.model
def check(self, mode, values=None):
"""Restricts the access to an ir.attachment, according to referred model
In the 'document' module, it is overriden to relax this hard rule, since
more complex ones apply there.
"""
# collect the records to check (by model)
model_ids = defaultdict(set) # {model_name: set(ids)}
require_employee = False
if self:
self._cr.execute('SELECT res_model, res_id, create_uid, public FROM ir_attachment WHERE id IN %s', [tuple(self.ids)])
for res_model, res_id, create_uid, public in self._cr.fetchall():
if public and mode == 'read':
continue
if not (res_model and res_id):
if create_uid != self._uid:
require_employee = True
continue
model_ids[res_model].add(res_id)
if values and values.get('res_model') and values.get('res_id'):
model_ids[values['res_model']].add(values['res_id'])
# check access rights on the records
for res_model, res_ids in model_ids.iteritems():
# ignore attachments that are not attached to a resource anymore
# when checking access rights (resource was deleted but attachment
# was not)
if res_model not in self.env:
require_employee = True
continue
records = self.env[res_model].browse(res_ids).exists()
if len(records) < len(res_ids):
require_employee = True
# For related models, check if we can write to the model, as unlinking
# and creating attachments can be seen as an update to the model
records.check_access_rights('write' if mode in ('create', 'unlink') else mode)
records.check_access_rule(mode)
if require_employee:
if not (self.env.user._is_admin() or self.env.user.has_group('base.group_user')):
raise AccessError(_("Sorry, you are not allowed to access this document."))
@api.model
def _search(self, args, offset=0, limit=None, order=None, count=False, access_rights_uid=None):
# add res_field=False in domain if not present; the arg[0] trick below
# works for domain items and '&'/'|'/'!' operators too
if not any(arg[0] in ('id', 'res_field') for arg in args):
args.insert(0, ('res_field', '=', False))
ids = super(IrAttachment, self)._search(args, offset=offset, limit=limit, order=order,
count=False, access_rights_uid=access_rights_uid)
if self._uid == SUPERUSER_ID:
# rules do not apply for the superuser
return len(ids) if count else ids
if not ids:
return 0 if count else []
# Work with a set, as list.remove() is prohibitive for large lists of documents
# (takes 20+ seconds on a db with 100k docs during search_count()!)
orig_ids = ids
ids = set(ids)
# For attachments, the permissions of the document they are attached to
# apply, so we must remove attachments for which the user cannot access
# the linked document.
# Use pure SQL rather than read() as it is about 50% faster for large dbs (100k+ docs),
# and the permissions are checked in super() and below anyway.
model_attachments = defaultdict(lambda: defaultdict(set)) # {res_model: {res_id: set(ids)}}
self._cr.execute("""SELECT id, res_model, res_id, public FROM ir_attachment WHERE id IN %s""", [tuple(ids)])
for row in self._cr.dictfetchall():
if not row['res_model'] or row['public']:
continue
# model_attachments = {res_model: {res_id: set(ids)}}
model_attachments[row['res_model']][row['res_id']].add(row['id'])
# To avoid multiple queries for each attachment found, checks are
# performed in batch as much as possible.
for res_model, targets in model_attachments.iteritems():
if res_model not in self.env:
continue
if not self.env[res_model].check_access_rights('read', False):
# remove all corresponding attachment ids
ids.difference_update(itertools.chain(*targets.itervalues()))
continue
# filter ids according to what access rules permit
target_ids = list(targets)
allowed = self.env[res_model].with_context(active_test=False).search([('id', 'in', target_ids)])
for res_id in set(target_ids).difference(allowed.ids):
ids.difference_update(targets[res_id])
# sort result according to the original sort ordering
result = [id for id in orig_ids if id in ids]
return len(result) if count else list(result)
@api.multi
def read(self, fields=None, load='_classic_read'):
self.check('read')
return super(IrAttachment, self).read(fields, load=load)
@api.multi
def write(self, vals):
self.check('write', values=vals)
# remove computed field depending of datas
for field in ('file_size', 'checksum'):
vals.pop(field, False)
if 'mimetype' in vals or 'datas' in vals:
vals = self._check_contents(vals)
return super(IrAttachment, self).write(vals)
@api.multi
def copy(self, default=None):
self.check('write')
return super(IrAttachment, self).copy(default)
@api.multi
def unlink(self):
self.check('unlink')
# First delete in the database, *then* in the filesystem if the
# database allowed it. Helps avoid errors when concurrent transactions
# are deleting the same file, and some of the transactions are
# rolled back by PostgreSQL (due to concurrent updates detection).
to_delete = set(attach.store_fname for attach in self if attach.store_fname)
res = super(IrAttachment, self).unlink()
for file_path in to_delete:
self._file_delete(file_path)
return res
@api.model
def create(self, values):
# remove computed field depending of datas
for field in ('file_size', 'checksum'):
values.pop(field, False)
values = self._check_contents(values)
self.browse().check('write', values=values)
return super(IrAttachment, self).create(values)
@api.model
def action_get(self):
return self.env['ir.actions.act_window'].for_xml_id('base', 'action_attachment')
通过修改IrAttachment模型中的_file_write,_file_read,_file_delete,_file_gc 等文件管理方法,改造其行为使用可以直接映射文件地址。
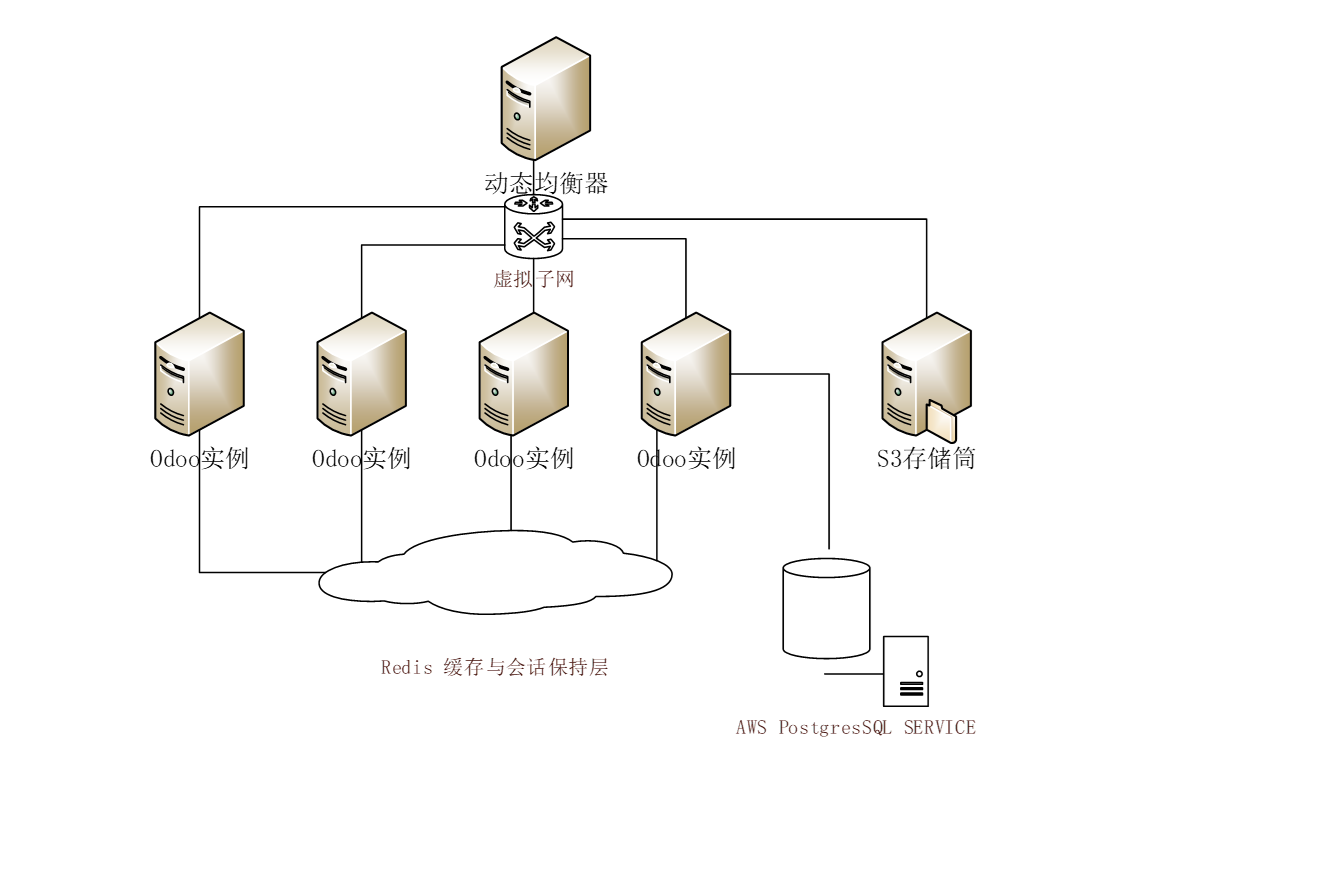
修改后架构